« Event Driven Architecture » : Mise en œuvre du pattern Circuit Breaker pour une meilleure résilience
Les architectures événementielles sont au cœur des applications Cloud natives d’aujourd’hui. Le pattern circuit breaker est une solution particulièrement efficace pour renforcer la résilience des systèmes et réduire considérablement les risques de défaillances globales.
Les nouveaux besoins de traitement instantané des événements, de scalabilité, de haute disponibilité et de connectivité vers le monde extérieur nécessitent de mettre en œuvre de nouveaux modèles d’architecture plus évolutifs.
Les architectures événementielles apportent une réponse pertinente à ces problématiques. Une étude menée par l’institut IDC[1] sur un panel de 300 entreprises de plus 1000 salariés, révèle que 47 % des entreprises interrogées utilisent déjà ce modèle d’architecture pour divers cas d’usage.
Les architectures événementielles ou « Event Driven Architecture », sont par nature basées sur la collaboration de services unitaires indépendants. Cette collaboration s’effectue majoritairement de manière asynchrone par publications de messages ou d’événements. En cas de défaillance d’un composant sollicité dans le traitement d’un événement, ce sont les traitements de centaines, voire de milliers d’événements qui vont échouer. Cela va provoquer des erreurs en cascade et potentiellement des blocages.
Un point clé pour l’augmentation de la disponibilité et de la résilience de ce type d’architecture est donc d’une part de mettre en place des mécanismes permettant d’éviter ces phénomènes d’erreur en cascade. D’autre part, il est également important d’assurer une reprise automatisée des traitements lors du retour à un fonctionnement nominal.
Dans cet article, nous détaillerons dans un premier temps les principes des architectures événementielles ainsi que ses principales caractéristiques.
Nous présenterons ensuite le fonctionnement du pattern Circuit Breaker . Nous montrerons comment l’usage de ce pattern permet d’éviter les erreurs en cascade en cas de défaillance d’un composant. Dans un second temps, comment il permet une reprise automatisée et progressive des traitements lors du retour à la normale.
Architecture événementielle : une réactivité optimale face aux défis d’aujourd’hui
Une architecture réactive réagissant en temps réel à des événements
Une architecture événementielle ou « Event Driven Architecture » est avant tout un « système réactif[2] » capable de réagir en temps réel à des événements. L’architecture repose sur des composants indépendants et faiblement couplés.
Dans ce modèle, les différents composants ne sont pas liés de manière fortement couplée. Ces derniers communiquent en émettant et en consommant des événements.
Par conséquent, ils peuvent être développés, testés et déployés de manière indépendante, sans affecter les autres composants. Cela rend ainsi le système plus souple et plus agile.
Architecture événementielle : 5 fondamentaux pour une architecture moderne
Pour une architecture événementielle performante, priorité à la modularité, la disponibilité, la résilience et à l’indépendance des composants. Voyons ensemble les principes qui en régissent son fonctionnement. Une architecture événementielle doit être :
- Disponible : le système doit continuer à fonctionner en cas d’incident impactant un composant. Chaque composant doit donc être multi instancié afin de permettre une tolérance aux pannes.
- Scalable: le système est capable de supporter une montée en charge importante sans impact majeur sur l’architecture.
- Résiliente: le système est capable de réagir à un incident afin de rester disponible et de s’auto réparer pour revenir automatiquement à sa capacité nominale.
- Basée sur des composants indépendants et faiblement couplés: Le système est conçu de manière modulaire sous la forme de composants indépendant. Les communications asynchrones basées sur des messages ou des notifications doivent être privilégiées lorsque cela est possible. Les communications asynchrones permettent un couplage lâche entre les composants.
- Orientée message: les composants du système communiquent de manière asynchrone en utilisant des événements. Chaque composant réagi en temps réel aux événements qu’il reçoit ou auxquels il est abonné.
Producteurs, gestionnaires, consommateurs : les piliers d’une architecture réactive
Une architecture événementielle repose sur une structure fondamentale composée de trois types de composants essentiels pour son bon fonctionnement : les producteurs d’événements, les gestionnaires d’événements et les consommateurs d’événements. Ces acteurs jouent un rôle crucial dans la dynamique réactive de ce système.
Les producteurs émettent généralement des messages afin de notifier d’un changement d’état du système ou de déclencher l’exécution d’un traitement ou d’un processus.
Les gestionnaires d’événements reçoivent les messages des producteurs et les diffusent aux consommateurs concernés selon différents patterns.
Enfin, les consommateurs d’événements traitent les messages reçus et effectuent les actions appropriées.
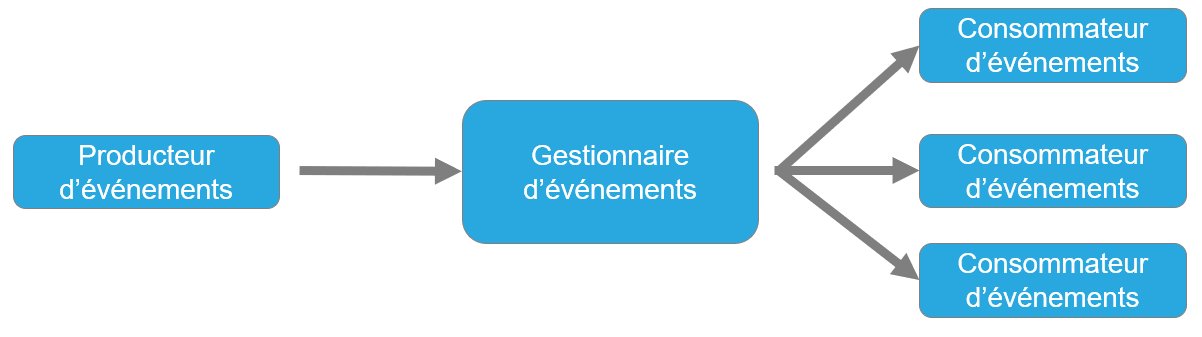
Figure 1 – Composants d’une architecture événementielle
Des services indépendants collaborant par des événements
Par essence, une architecture événementielle est modulaire. Elle est en effet conçue comme un ensemble de composants indépendants qui collaborent par des événements.
Le traitement d’un événement s’apparente à un workflow plus ou moins complexe d’appel d’API, d’envoi de messages et de publication d’événements.
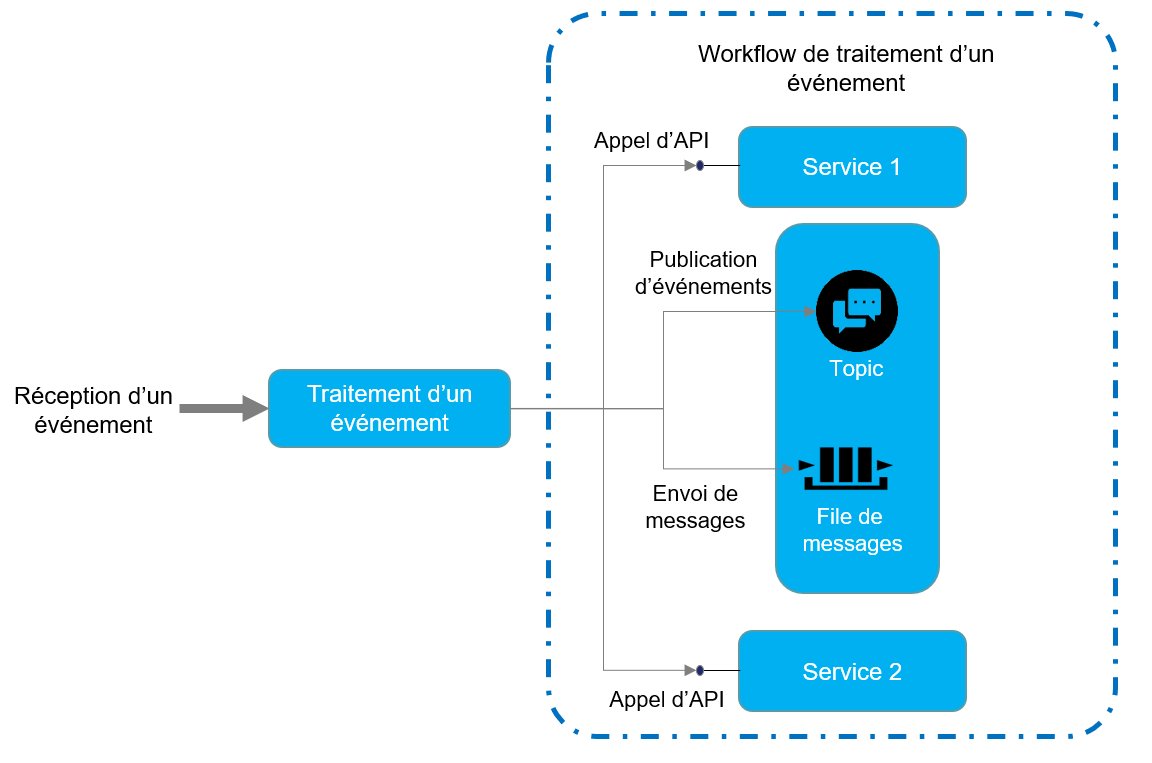
Figure 2 -Workflow de traitement d’un événement
Une architecture distribuée pour une plus grande scalabilité et résilience
Chaque composant est redondé, ce qui assure la haute disponibilité et peut monter en charge sans impact sur le reste du système. En effet, chaque service étant déployé séparément, son nombre d’instance peut varier dynamiquement en fonction de la charge, de manière indépendante des autres services.
À cet effet, l’utilisation de mécanismes d’autoscaling peut être envisagée, permettant ainsi une gestion automatique et efficace des ressources
La haute disponibilité et la résilience est également accrue par l’usage de modes d’échange asynchrones rendant indépendant le producteur et le consommateur d’un événement.
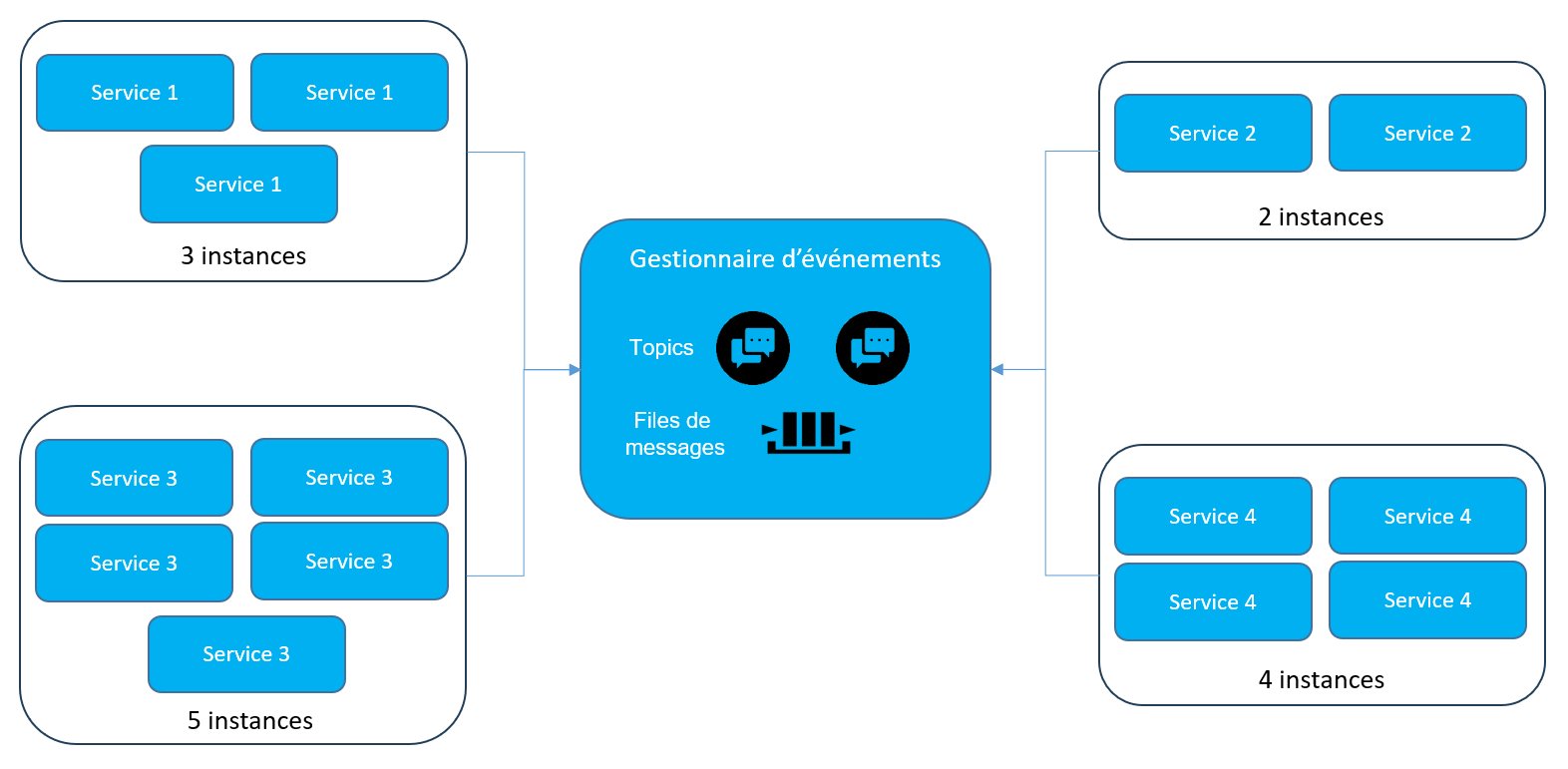
Figure 3 – Exemple d’instanciation dynamique des services
Par ailleurs, l’asynchronisme permet également de réguler le trafic et ainsi d’éviter les saturations. En effet, une file de message ou d’un Topic agit comme un tampon entre les producteurs et les consommateurs d’un événement.
Le nombre de consommateur d’un événement peut être défini afin de réguler le débit et éviter ainsi les phénomènes de saturation en cas de pic de trafic. Ce principe permet notamment de réguler les accès à une base de données ou à un système ayant une scalabilité limitée.
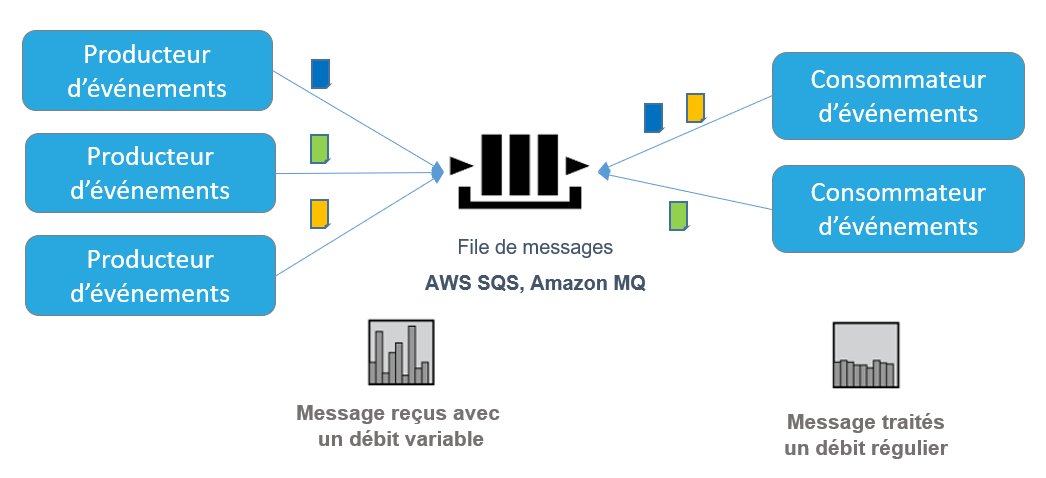
Figure 4 – Utilisation d’une file de message comme tampon entre les producteurs et consommateurs d’événements.
Une plus grande complexité liée à la distribution et à l’asynchronisme
Une application basée sur une architecture événementielle est composée d’un ensemble de composants et de services indépendants et faiblement couplés qui collaborent par le biais d’événements.
Un composant peut donc générer des événements qui seront traités par un ou plusieurs services selon le modèle de publication. Ces services peuvent eux-mêmes produire d’autres événements.
Prenons l’exemple d’une validation de commande sur un site de commerce électronique. Le traitement de cet événement peut être effectué par un ensemble de services. Et ces derniers peuvent être distribués sur plusieurs nœuds ou même sur des plateformes différentes.
Cette distribution des traitements ainsi que les communications asynchrones entre les composants engendrent :
- Une plus grande difficulté à suivre le traitement d’un événement de bout en bout, notamment en cas d’anomalie,
- Une plus grande complexité d’analyse des comportements basés sur un ensemble de composants distribués.
Il devient donc impératif d’avoir une plus grande rigueur dans l’urbanisation du système afin d’éviter l’effet spaghetti. Par ailleurs, il convient de mettre en place des outils d’observabilité permettant d’auditer les événements d’un workflow.
Un traitement automatisé des erreurs : un point clé pour la résilience des architectures événementielles
Dans une architecture distribuée, l’appel à une ressource distante tel qu’un appel d’API ou l’accès à une base de données, peut échouer en raison d’un problème temporaire. Ce type d’erreur peut être lié par exemple à un problème réseau, à une saturation ou à l’indisponibilité de la ressource accédée.
Dans ce cas, tous les traitements ayant besoin d’accéder cette ressource vont échouer provoquant des retry en cascade, la saturation et le blocage du système.
Lors du retour à la normale, la reprise des traitements de centaines voire de milliers d’événements peut s’avérer complexe et très impactant pour le fonctionnement du système.
Ainsi, lorsque l’indisponibilité d’une ressource est avérée, il peut être préférable de suspendre les traitements devant accéder à cette ressource en attendant que celle-ci soit à nouveau disponible.
Dans un système fortement distribué, il est essentiel d’accorder une attention particulière au traitement des erreurs, en mettant l’accent sur la gestion automatique des tentatives de réexécution (retry) en cas d’échec lors du traitement d’un événement. Cette gestion automatique des tentatives est cruciale pour assurer le bon fonctionnement du système.
Cette gestion est rendue particulièrement complexe par la distribution des traitements et l’asynchronisme. Il est donc fondamental de concevoir cette gestion des erreurs comme une partie intégrante du processus et non comme des traitements génériques mis en place a posteriori.
Comment le pattern « Circuit Breaker » permet d’améliorer la résilience des architectures événementielles
Qu’est qu’un « Circuit Breaker » ?
Le Circuit Breaker est un pattern permettant de suspendre des traitements lorsque des échecs à répétition sont constatés. Ainsi lorsqu’une ressource distante telle qu’une base de données ou un service est inaccessible, le pattern Circuit Breaker permettra d’interrompre l’exécution des traitements faisant appel à cette ressource, évitant ainsi des erreurs en cascade.
Comme son nom l’indique, un Circuit Breaker se comporte comme un coupe circuit. En situation normale, le circuit est fermé et le trafic peut donc s’écouler normalement.
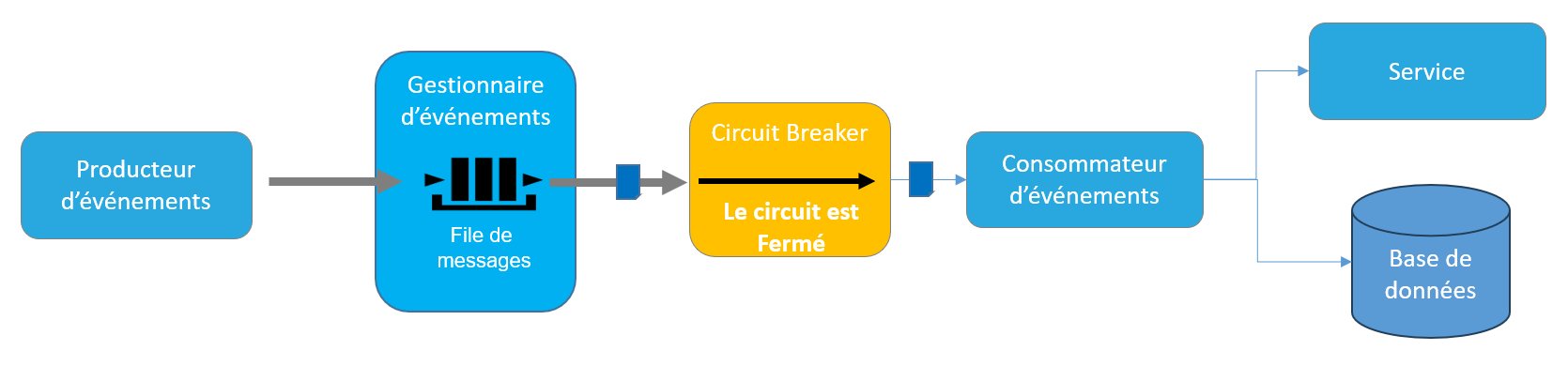
Figure 5 – Le circuit est Fermé. Le trafic est passant
En cas de problème récurrent, le circuit passe en position ouverte, arrêtant ainsi le traitement du flot d’événement en attendant un retour à la normale.
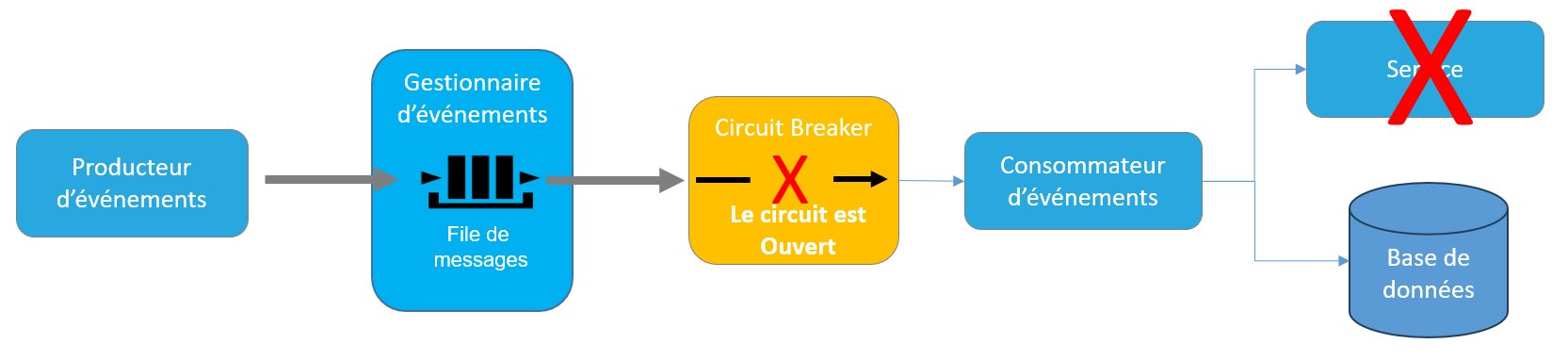
Figure 6 – Le circuit est ouvert. Le trafic est interrompu
Un Circuit Breaker possède trois états :
- Fermé: Le circuit est fermé permettant ainsi aux événements d’être consommés. Le Circuit Breaker se comporte comme un proxy et comptabilise le nombre d’erreur rencontrées. Lorsque le taux d’erreur atteint un seuil critique, le proxy passe en état ouvert stoppant ainsi, pendant un temps déterminé, le traitement des événements en attente. A l’issue de ce temps, le circuit passe dans l’état Semi-Ouvert permettant ainsi le traitement d’un nombre limité d’événements.
- Ouvert : Le circuit est ouvert et les événements cessent d’être consommés pendant un temps déterminé, ce temps étant défini en fonction des cas d’usage. L’objectif est de suspendre l’exécution des traitements en attendant la résolution du problème et un potentiel retour à une situation normale.
- Semi-Ouvert: dans cet état, le Circuit Breaker permet de traiter un nombre limité d’événements. Si tous les événements sont traités avec succès, alors le problème est considéré comme résolu et le circuit passe à l’état Fermé autorisant ainsi le traitement de l’ensemble des événements en attente. Si le traitement de l’un des événements échoue, alors le circuit repasse à nouveau à l’état Ouvert interrompant ainsi le traitement des événements pendant un temps donné.
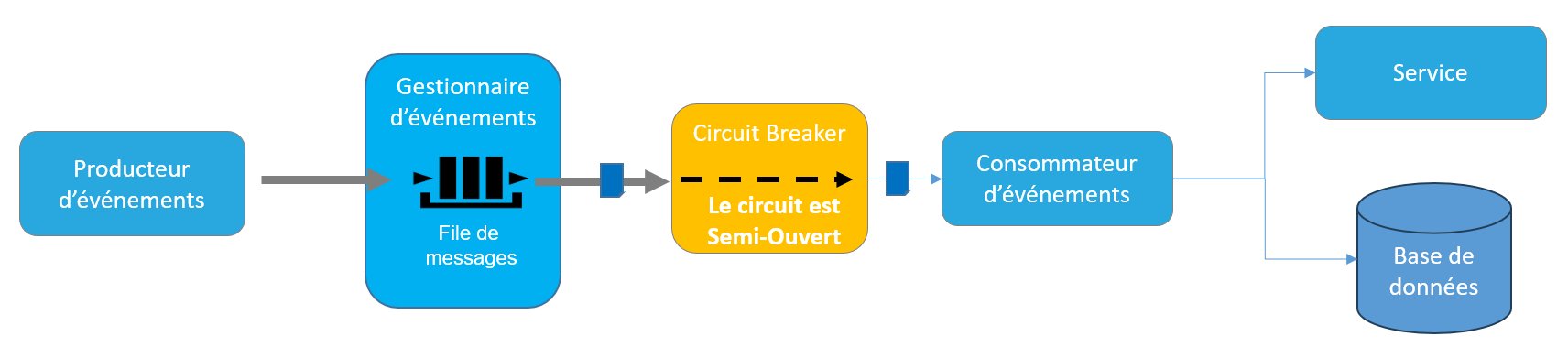
Figure 7 – Le circuit est Semi-Ouvert. Seul un nombre limité d’événements est consommé
Le schéma suivant détaille les états d’un Circuit Breaker et les conditions de changement d’états :
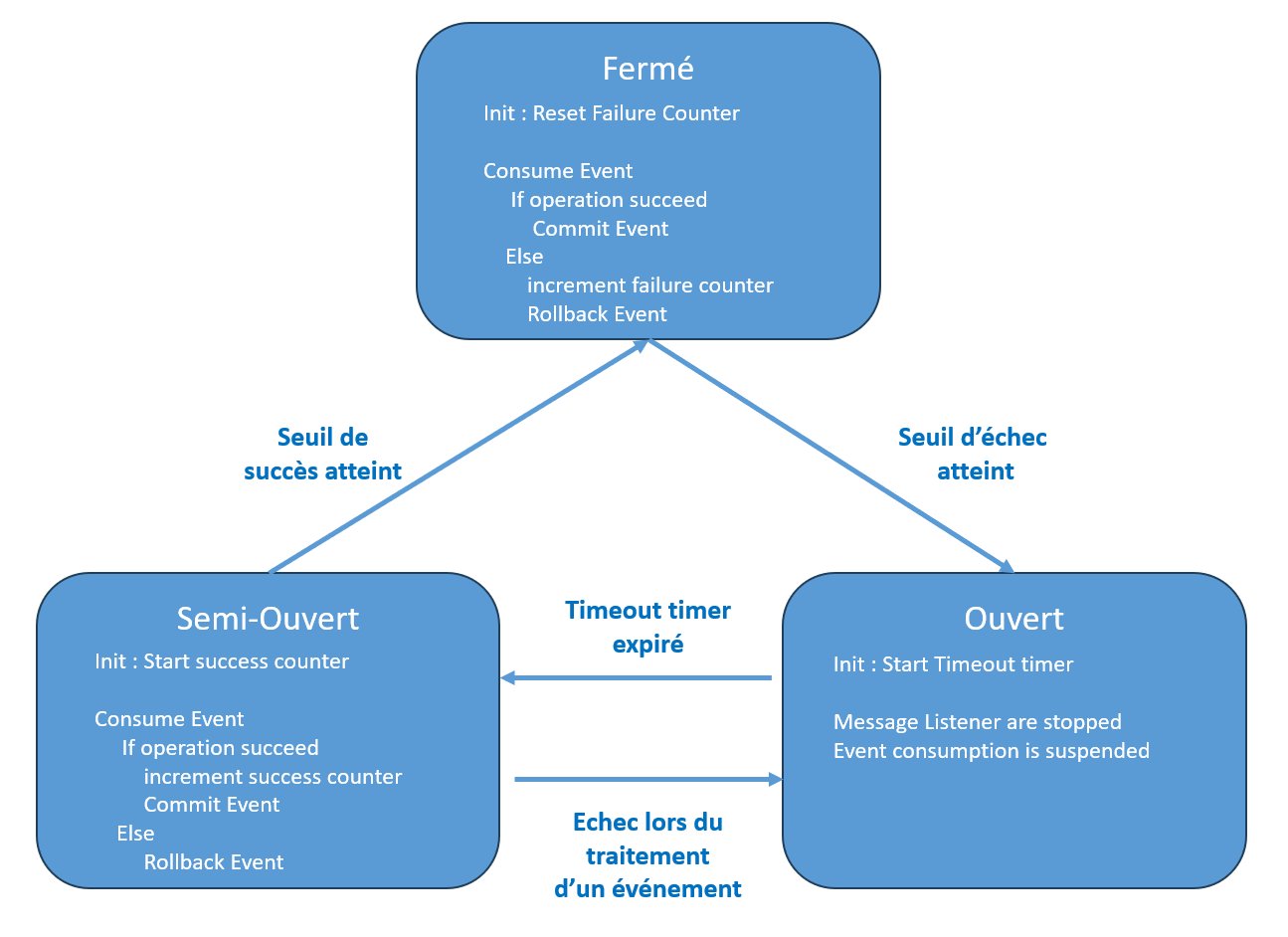
Figure 8 – Etats et cycle de vie d’un Circuit Breaker
Comment le pattern « Circuit Breaker » permet d’améliorer la résilience en cas de défaillance d’un composant
La mise en œuvre d’un Circuit Breaker permet donc d’éviter des erreurs à répétition lorsqu’une ressource invoquée par un service ne répond pas ou retourne systématiquement une erreur.
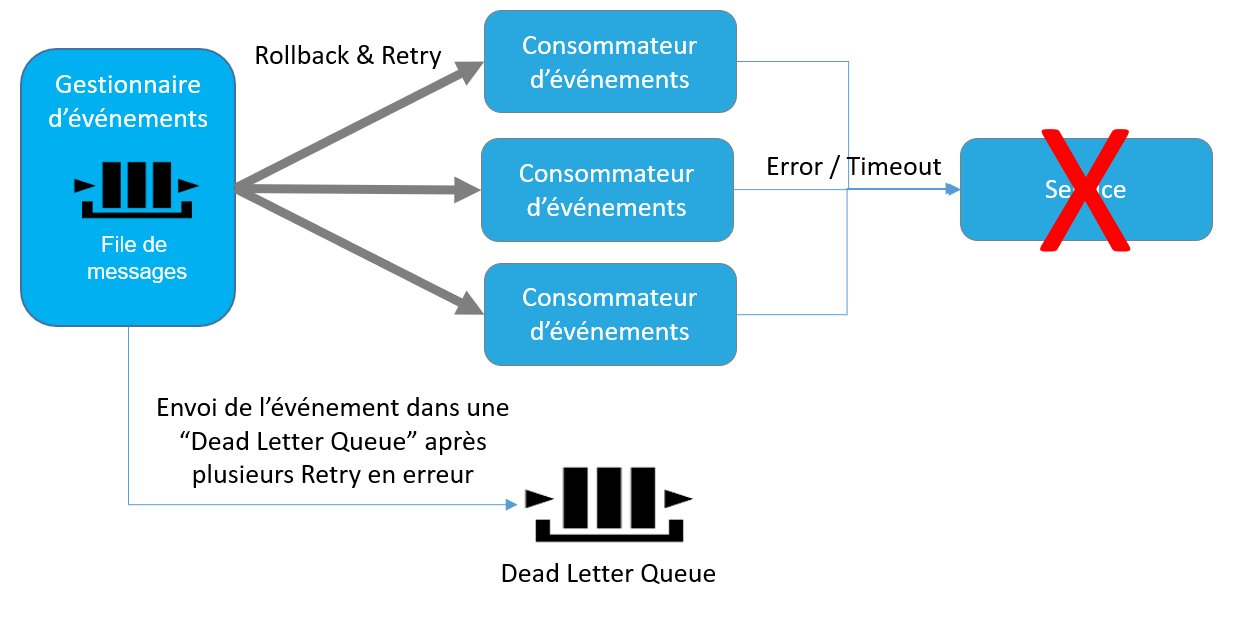
Figure 9 – Consommation d’un événement sans Circuit Breaker
Ce mécanisme permet donc de différer le traitement d’un événement lorsque celui-ci a une très grande probabilité d’échec.
Le traitement d’un événement étant par nature asynchrone, un traitement différé de cet événement n’a pas d’impact notable sur le fonctionnement global du système. Cette approche permet ainsi d’éviter des phénomènes de saturation et de blocage dus à des timeout d’appel sur la ressource en erreur.
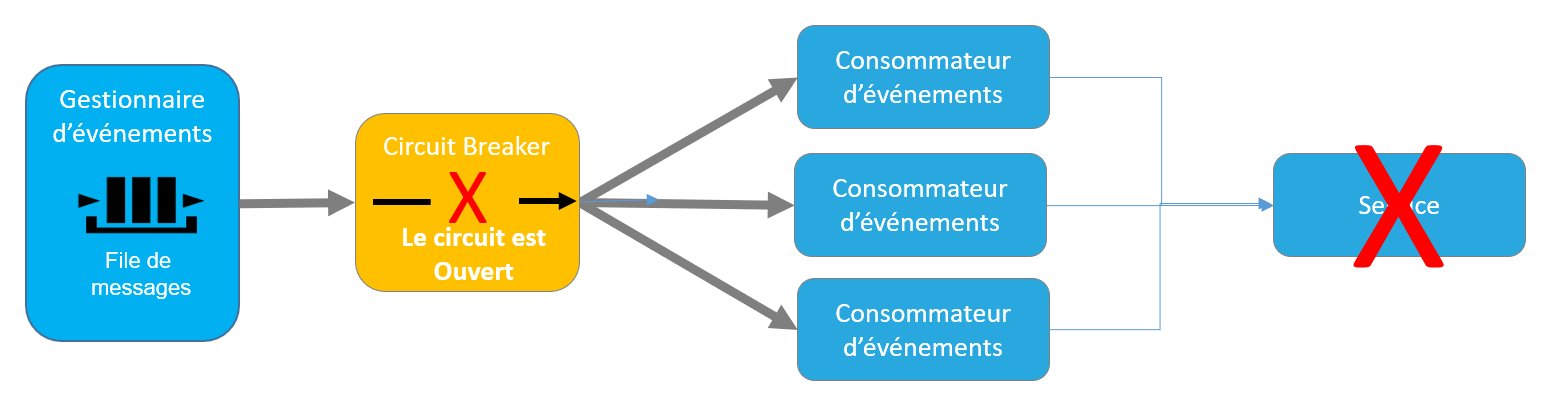
Figure 10 – Consommation d’un événement avec un Circuit Breaker
Comment implémenter ce pattern dans une architecture distribuée
La problématique
Dans une architecture événementielle, les services sont multi instanciés et distribués sur plusieurs nœuds physique afin d’assurer la scalabilité et la haute disponibilité du système.
Deux stratégies sont dès lors possibles pour la mise en œuvre d’un Circuit Breaker :
- Le Circuit Breaker est centralisé et partagé par toutes les instances d’un service
- Chaque instance de service possède son propre Circuit Breaker
Une implémentation centralisée pour l’ensemble des instances d’un service
Le Circuit Breaker est dans ce cas centralisé et commun à l’ensemble des instances d’un même service. Cette stratégie pose le problème de la haute disponibilité et de la scalabilité du Circuit Breaker.
Le Circuit Breaker devient un point de contention pouvant poser des problèmes de scalabilité en cas de fort trafic. Il devient également un point de faiblesse pouvant interrompre le fonctionnement du système en cas de défaillance.
De ce fait, cette stratégie d’implémentation, plus complexe à implémenter, n’est pas recommandée.
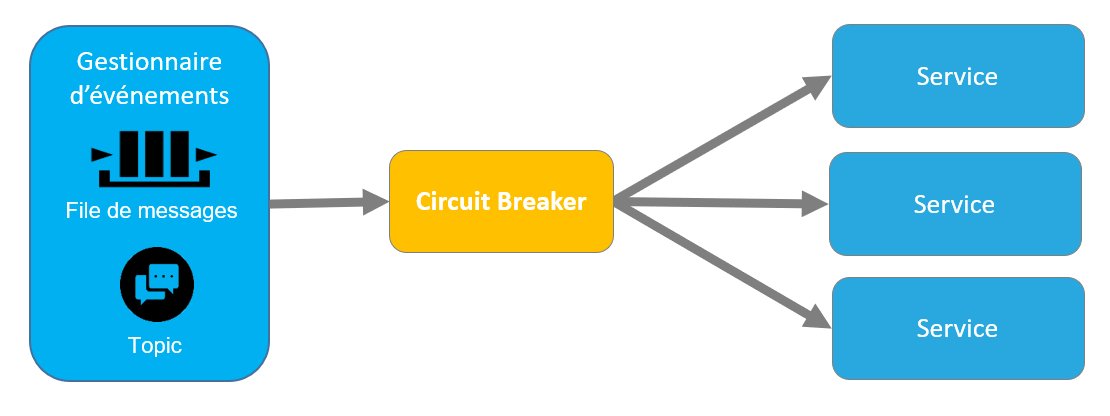
Figure 11 – Circuit Breaker centralisé commun à toutes les instances d’un service
Une implémentation distribué au niveau de chaque instance d’un service
Dans ce cas, chaque instance de service possède son propre Circuit Breaker. Le Circuit Breaker est intégré au service qui est indépendant des autres instances.
La scalabilité et la haute disponibilité du système sont dans ce cas assurées par la multi instanciation des services et ne sont pas impactées par la mise en œuvre du Circuit Breaker.
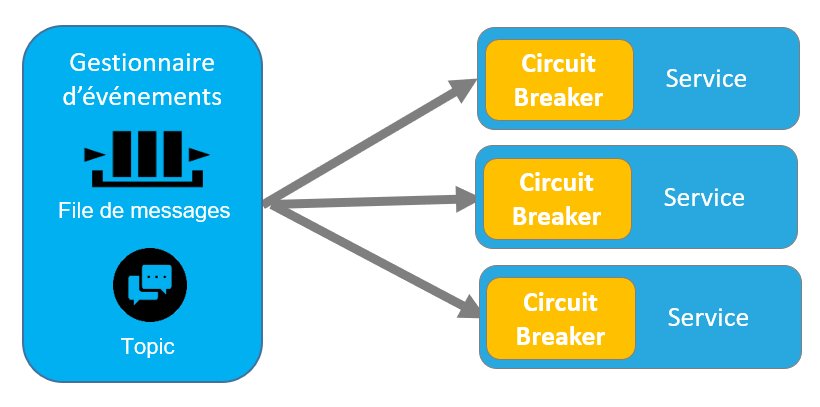
Figure 12 – Circuit Broker distribué au niveau de chaque instance d’un service
Exemple d’implémentation sur la plateforme Cloud AWS
Mise en œuvre d’un Circuit Breaker avec SQS
Dans le cas d’une architecture événementielle, lorsque le Circuit Breaker passe à l’état ouvert, l’interruption du trafic doit s’accompagner d’une interruption de la lecture des messages présents dans la file de message ou le Topic.
Ainsi dans le cas d’un gestionnaire de file de message tel que SQS supportant JMS (Java Message Service), la lecture des messages par les listeners JMS doit être suspendue.
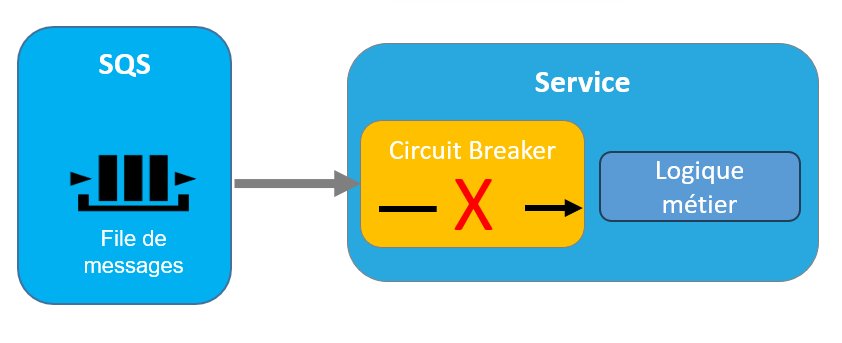
Figure 13 – Circuit Breaker en état Ouvert
Le circuit est ouvert ; Les Listeners JMS sont suspendus et les messages ne sont plus consommés.
Lorsque le Circuit Breaker passe à l’état semi-ouvert, le trafic reprend partiellement. Dans ce cas, les listeners JMS sont réactivés avec un seul thread ou un nombre limité de thread, permettant ainsi une reprise du trafic avec un débit limité afin de tester le bon fonctionnement du service.
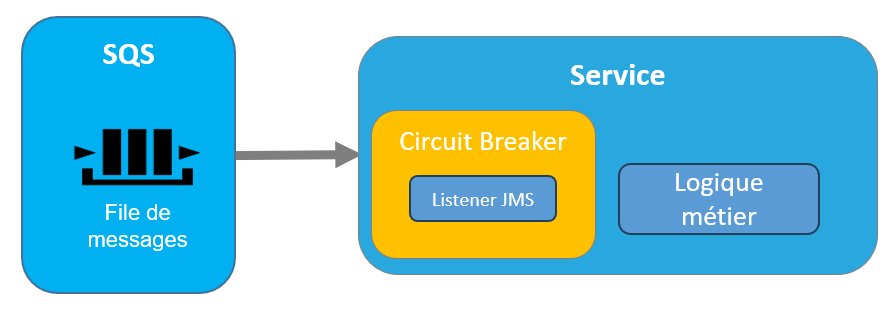
Figure 14 – Circuit Breaker en état Semi-Ouvert
Lorsque le Circuit Breaker passe à l’état fermé, tous les listeners JMS sont réactivés. L’ensemble des threads consommant les messages redeviennent actifs. Le trafic reprend normalement.
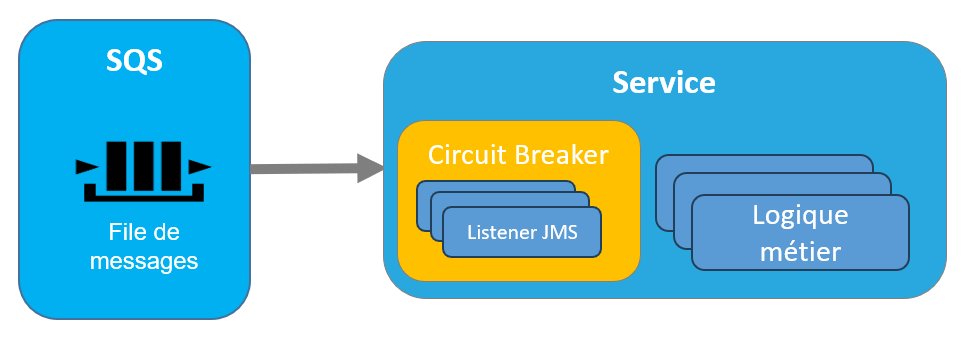
Figure 15 – Circuit Breaker en état Fermé
Mise en œuvre d’un Circuit Breaker dans un Cluster Kubernetes
Dans le cas de microservices déployés dans un cluster Kubernetes EKS et consommant des messages dans des files SQS ou des topics Kafka, chaque instance de service possède son propre Circuit Breaker fonctionnant en autonomie indépendamment des autres instances.
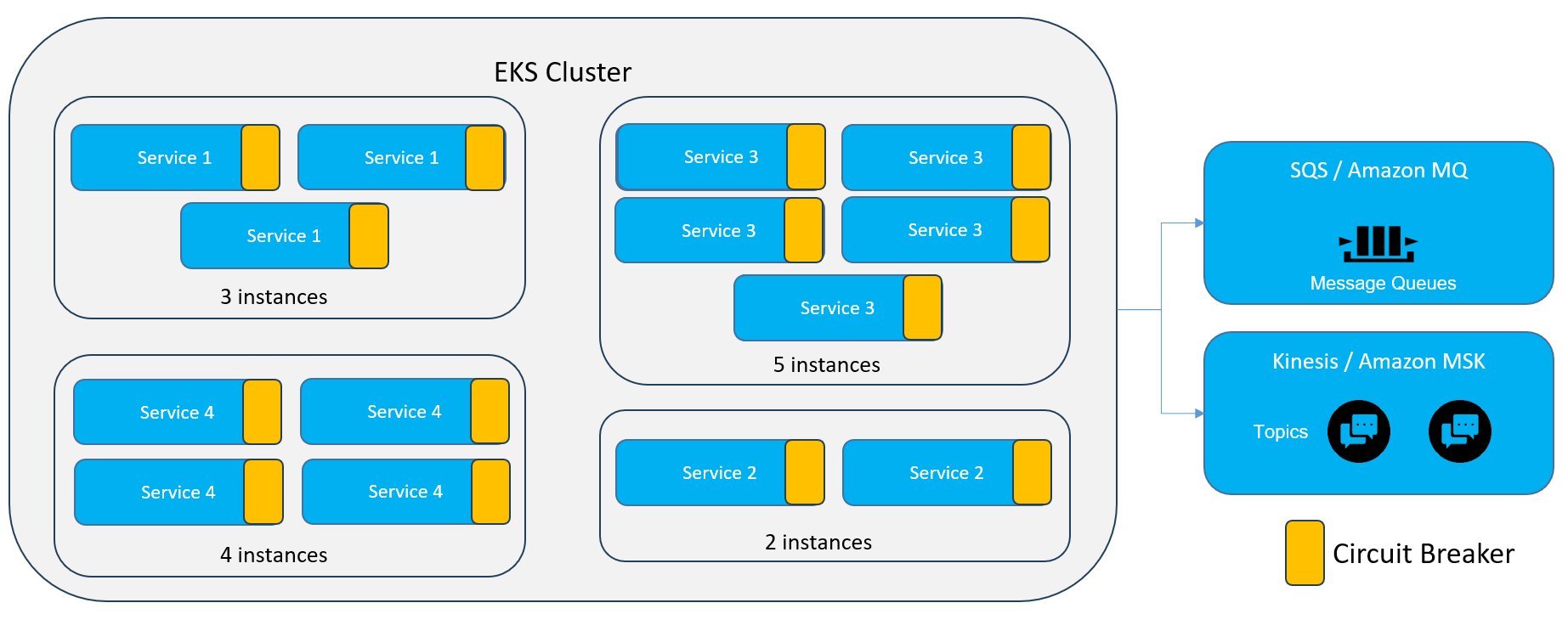
Figure 16 – Circuit Breaker instanciés dans un cluster Kubernetes
Quand utiliser ce pattern ?
Il est recommandé d’utiliser ce pattern lorsque le traitement d’un événement fait appel à un service distant pouvant être indisponible ou subir des phénomène de saturation.
En revanche, l’utilisation de ce mécanisme n’est pas recommandée lors de l’accès à une ressource locale ou bien une ressource partagée en mémoire. En effet, l’accès à la ressource étant dans ce cas très rapide, la mise en œuvre d’un Circuit Breaker va entraîner une latence importante.
Le Circuit Breaker ne doit pas être utilisé en lieu et place d’un traitement approprié des erreurs. En effet ce pattern permet une suspension et une régulation du trafic dans le cas d’erreurs techniques répétées provoquées par un phénomène temporaire.
Dans le cas d’erreurs fonctionnelles provoquées par exemple par l’envoi de requêtes incorrectes ou incomplètes, un traitement d’erreur doit dans ce cas être appliqué afin de rejeter ces requêtes et les placer par exemple dans une « Dead Letter Queue ».
Circuit Breaker : un pattern efficace pour améliorer la résilience des systèmes distribués
Comme nous l’avons vu dans cet article, le pattern Circuit Breaker est donc un moyen simple et efficace d’améliorer la résilience des architectures événementielles et des systèmes distribués en général.
Il peut s’implémenter très simplement au niveau de chaque instance de service en utilisant notamment des Frameworks tel que Resilience4J qui proposent une implémentation robuste et prête à l’emploi.
L’utilisation conjointe de ce Framework et de Spring Boot, Spring JMS ou Spring Kafka, selon le broker utilisé, permet une mise en œuvre très rapide de ce pattern pour une implémentation Java d’un microservice.
[1] “Getting in Sync: Unlocking the Exponential Business Value of Real-Time Event-Driven Data Flows”, solace.com, Unlocking the Exponential Business Value of Real-Time Event-Driven Data Flows, 2023
[2] Jonas Bonér, Dave Farley, Roland Kuhn, and Martin Thompson, « Le Manifeste Réactif », reactivemanifesto.org, 16 septembre 2014.
Auteur
-

Eric Datei
Leader Senior IT Architect - Cloud