Javanalyser cartographie vos programmes Java pour une maintenance simplifiée
La maintenabilité des logiciels, difficile à mesurer pèse lourd sur les budgets et la performance des équipes. Javanalyser promet de changer la donne en cartographiant le code pour mieux l’analyser.
Le coût prohibitif de la mauvaise structure des programmes
La maintenabilité est un enjeu central en programmation informatique. Dès 1968, Dijkstra publie un article emblématique de cette préoccupation : « Go To Statement Considered Harmful[1] ». Selon l’auteur, la qualité du code est une fonction décroissante de la densité d’instructions GOTO. Cette dernière réalise un saut inconditionnel à n’importe quel autre endroit du programme. L’argument de l’auteur implique deux prémisses :- L’objet principal d’un programme réside dans son processus dynamique de traitement de l’information ;
- Les capacités cognitives des programmeurs sont orientées vers la maîtrise des relations statiques plutôt que la visualisation des processus dynamiques.
De la modélisation de la maintenabilité aux métriques
Les modèles de maintenabilité s’inscrivent dans le cadre plus général des modèles de qualité logicielle. Un modèle de qualité logicielle a pour objectif de fournir un cadre à l’analyse d’un programme vis-à-vis d’un ensemble de qualités définies par le modèle. Il est possible de classer les modèles de qualité logicielle en trois catégories de modèles : théoriques, concrets et empiriques[4].Les modèles théoriques comme taxonomie de la maintenabilité
Les modèles théoriques se présentent sous la forme d’une hiérarchie de qualité logicielle. Ainsi, ils définissent la maintenabilité en la découpant en sous-caractéristiques. Ce processus peut être récursif, mais en pratique les modèles se limitent à deux ou trois niveaux. Les relations entre les niveaux hiérarchiques de qualité peuvent être de type plusieurs-à-plusieurs ou un-à-plusieurs. Dans ce deuxième cas, un modèle théorique de maintenabilité définit alors un arbre de qualités logicielles dont la racine est la maintenabilité. Les sous-caractéristiques de bas niveau, « feuilles », sont parfois associées à une ou plusieurs métriques. Pour rappel, une métrique est une mesure quantitative effectuée sur un programme ou son processus de développement. Les modèles théoriques ne définissent pas de méthode d’évaluation de la maintenabilité à partir des scores des sous-caractéristiques.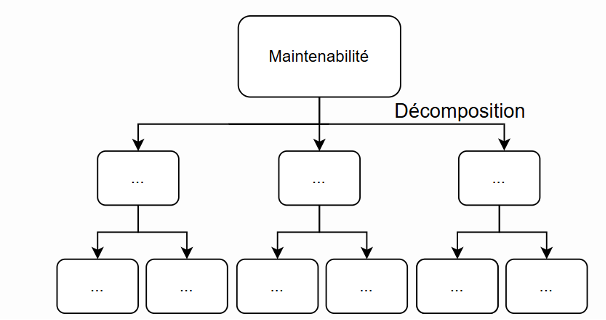
Les modèles concrets pour opérationnaliser l’évaluation de la maintenabilité
Les modèles concrets de maintenabilité sont apparus dans les années 2000. Ils reprennent avec plus ou moins de fidélité un modèle théorique qui sert alors de base à la construction du modèle concret. Ils se distinguent des modèles théoriques par leur proposition d’une méthode opérationnelle d’évaluation de la maintenabilité. En particulier, ils définissent une mécanique d’agrégation des scores « feuilles » qui permet d’obtenir une note globale de maintenabilité. L’objectif de ces modèles est d’être plus détaillés que les modèle théoriques et plus explicables que les modèles empiriques.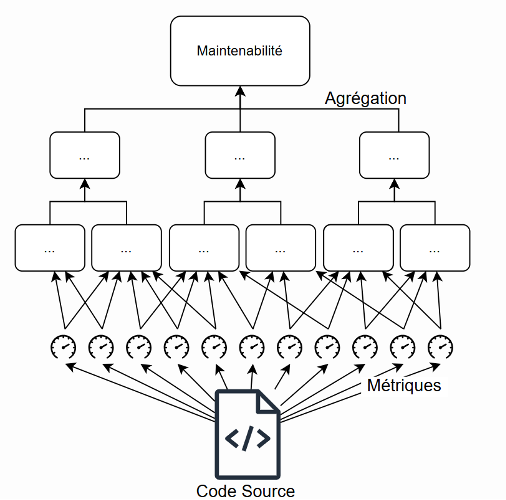
Les modèles empiriques pour une prédiction centrée sur les données
Les modèles empiriques s’appuient sur des jeux de données expérimentaux pour entrainer des algorithmes de prédiction de la maintenabilité logicielle. Le principe général des modèles empiriques consiste à construire une formule pour représenter la maintenabilité sous la forme d’une combinaison de métriques. Ainsi, la maintenabilité est « apprise » à partir des métriques puis « prédite » sur la base de cet apprentissage. En d’autres termes, on utilise des mesures pour estimer à quel point un logiciel sera facile à maintenir. En 1992, les chercheurs Paul Oman et Jack Hagemeister ont introduit l’« index de maintenabilité[5] » qui introduit cette approche. Le développement des méthodes d’apprentissage automatiques et des réseaux de neurones a rendu omniprésent ce type de modélisation dans les études modernes de la maintenabilité logicielle.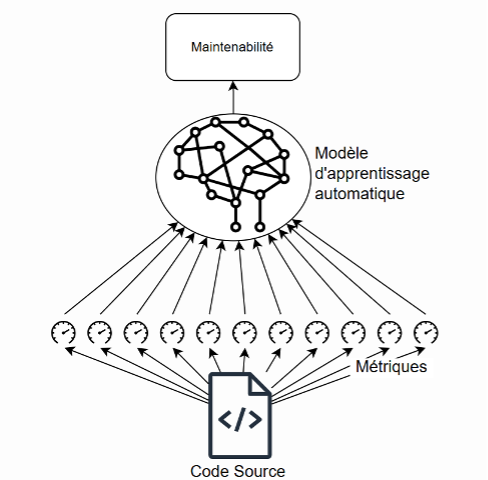
Les métriques comme tête de lecture des modèles
Les métriques contribuent à représenter le code source afin d’évaluer la maintenabilité. Les métriques statiques de code sont basiquement des compteurs. Elles décomptent des éléments spécifiques du code source en agrégeant les résultats à une granularité donnée. Les règles de décompte sont souvent très simples. À partir de ces métriques « compteur », il est possible de définir des métriques dérivées qui seront par exemple la moyenne ou le maximum d’une métrique de base. Il est possible de classifier les métriques statiques en quatre catégories :- Les métriques de taille quantifient le code source en termes de « volume », comme le nombre de lignes de code.
- Les métriques de contrôle s’intéressent aux flux de contrôle des fonctions.
- Les métriques d’invocations analysent les dépendances entre fonctions.
- Les métriques objet sont spécifiquement conçues pour les langages orientés objet.
La fiabilité des métriques en question
Malheureusement, les métriques souffrent de plusieurs limites. Il existe de nombreux outils de calcul des métriques. Mais la sélection des métriques implémentées varie grandement entre les outils. Et par ailleurs, les résultats pour une métrique donnée montrent peu de concordance, même pour une métrique aussi simple que le nombre de lignes de code. De plus, il existe un effet confondant du nombre de lignes de code sur les autres métriques logicielles, ce qui jette le doute sur leur utilité. Enfin, dans de nombreux cas, l’utilisation opérationnelle des métriques pose des problèmes théoriques vis-à-vis des fondements scientifiques de la mesure. Ce qui tend à suggérer une simple corrélation entre les métriques et la maintenabilité, sans relation de causalité. Il existe une complexité structurelle au-delà de la taille d’un programme ou de ses composants. Étant donné que les métriques incarnent le programme auprès des modèles de maintenabilité, il est indispensable de prendre en compte leurs limites pour construire un modèle de maintenabilité.Javanalyser pour analyser le code à l’aide de graphes
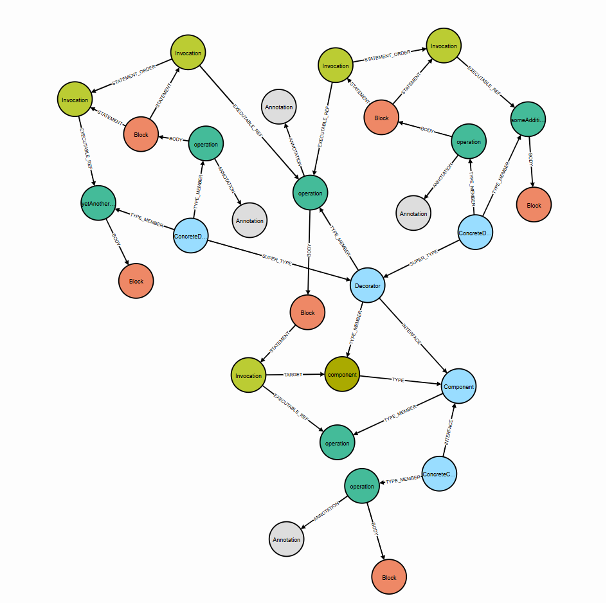
Comment modéliser opérationnellement la structure du code source d’un programme ? L’objectif est ici de modéliser structurellement la maintenabilité logicielle, c’est-à-dire en ignorant la présentation et le nommage des éléments de programme. En termes de représentation, le code source d’un logiciel constitue une structure rigide qui obéit à des règles strictes. Il peut donc être représenté sous forme de graphe de code. Ces derniers sont une représentation idéale, complète et encore peu exploitée pour l’analyse statique de la maintenabilité de la structure du code source. Dans ce cadre, un outil appelé Javanalyser a été développé afin de générer automatiquement des graphes de code à partir de l’arbre syntaxique abstrait d’un programme Java[6]. Il est publié sous la licence libre MIT. Son principe de fonctionnement est relativement simple. Il analyse le code d’un programme Java en trois étapes :- Construction de l’arbre syntaxique de code ;
- Repliement de l’arbre en graphe ;
- Chargement du graphe dans une base de données orientée graphe (Neo4j).

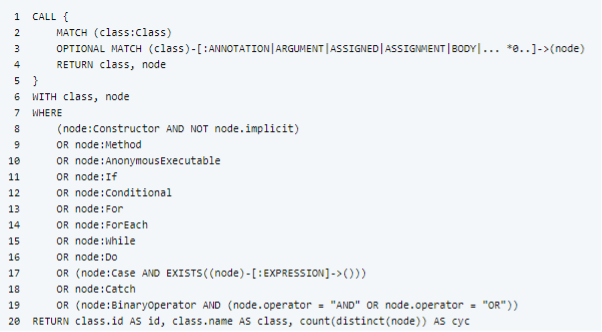
- la sélection des éléments de programme appartenant à une classe (lignes 2 à 4) ;
- le filtrage des éléments à prendre en compte dans le calcul (lignes 7 à 19) ;
- le décompte final de la métrique (ligne 20).
La prédiction de maintenabilité par apprentissage automatique
Les métriques logicielles ainsi formalisées, il devient possible de prédire la maintenabilité logicielle grâce aux méthodes d’apprentissage automatique. Cette approche représente les graphes du code sous la forme de vecteurs de métriques. Ces vecteurs de variables sont ensuite utilisés pour entrainer des classifieurs statistiques. Dans le prolongement des avancées récentes, des chercheurs de l’Université Technique de Munich ont constitué un jeu de données de référence reposant sur près de 2000 évaluations de maintenabilité fournies par 70 professionnels issus de divers secteurs industriels. Ce corpus repose sur des jugements experts portant sur des classes Java, en intégrant plusieurs sous-dimensions de la maintenabilité (comme la lisibilité, la complexité ou la taille) et en tenant compte de l’importance relative accordée à chacune[7]. Ce jeu de données a ensuite été utilisé pour entraîner des modèles capables de prédire automatiquement la maintenabilité perçue, avec des performances comparables à celles d’un évaluateur humain moyen[8]. La figure suivante illustre ce jeu de données, chaque point représentant une classe positionnée selon sa taille et son niveau de maintenabilité. Comme évoqué précédemment, la taille des classes Java est un facteur confondant important pour l’ensemble de métriques et a fortiori pour la prédiction de maintenabilité.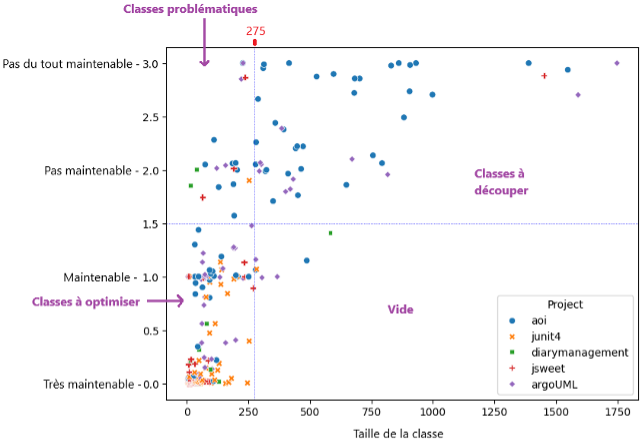
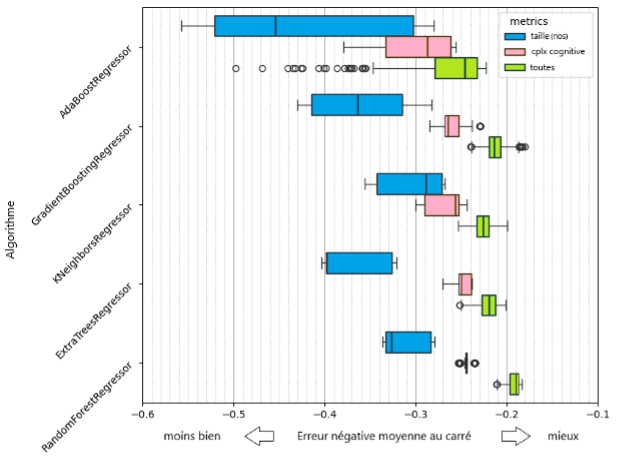
- Seulement la taille,
- Seulement la complexité cognitive
- Et l’ensemble des 33 métriques formalisées.
Javanalyser : une meilleure compréhension et gestion de la maintenabilité logicielle
L’évaluation de la maintenabilité est une construction humaine qui est propre à chaque développeur et à chaque contexte. L’objectif de ces travaux est d’identifier les quantités structurelles fondamentales qui caractérisent la maintenabilité du graphe de code d’un programme, mais l’évaluation de cette maintenabilité finale est dépendante du contexte. Les perspectives de recherches futures s’articulent principalement autour de deux axes :- La généralisation des métriques statiques de code ;
- La construction d’un modèle structurel de maintenabilité.
[1] Edgard Dijkstra, « Go To statement considered harmful », Commun. ACM, vol. 11, no 3, p. 147‑148, doi: 10.1145/362929.362947, mars 1968.
[2] R. C. Martin, « Clean code: a handbook of agile software craftmanship », 464 pages, Prentice Hall International, 2008.
[3] G. Canfora et A. Cimitile, « Software maintenance, in Handbook of Software Engineering and Knowledge Engineering », 2 vol., World Scientific Publishing Company, p. 91‑120. doi: 10.1142/9789812389718_0005, 2001.
[4] R. Ferenc, P. Hegedüs, et T. Gyimóthy, « Software product quality models », in Evolving software systems, T. Mens, A. Serebrenik, et A. Cleve, Éd., Berlin Heidelberg: Springer-Verlag, p. 65‑100. doi: 10.1007/978-3-642-45398-4, 2014.
[5] P. Oman et J. Hagemeister, « Construction and testing of polynomials predicting software maintainability », J. Syst. Softw., vol. 24, no 3, p. 251‑266, mars 1994, doi: 10.1016/0164-1212(94)90067-1.
[6] S. Bertrand, P.-A. Favier, et J.-M. André, « Building an operable graph representation of a Java program as a basis for automatic software maintainability analysis », in EASE ’22: Proceedings of the International Conference on Evaluation and Assessment in Software Engineering 2022, in EASE 2022. Gothenburg, Sweden: Association for Computing Machinery, juin 2022, p. 243‑248. doi: 10.1145/3530019.3534081.
[7] M. Schnappinger, A. Fietzke, et A. Pretschner, « Defining a software maintainability dataset: collecting, aggregating and analysing expert evaluations of software maintainability », in 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), Adelaide, Australia: IEEE, sept. 2020, p. 278‑289. doi: 10.1109/ICSME46990.2020.00035.
[8] M. Schnappinger, A. Fietzke, et A. Pretschner, « Human-level ordinal maintainability prediction based on static code metrics », in EASE 2021: Evaluation and Assessment in Software Engineering, Trondheim, Norway: ACM, juin 2021, p. 160‑169. doi: 10.1145/3463274.3463315.
[9] S. Bertrand, S. Ciappelloni, P.-A. Favier, et J.-M. André, « Replication and extension of Schnappinger’s study on human-level ordinal maintainability prediction based on static code metrics », in Proceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering, in EASE ’23. Oulu, Finland: Association for Computing Machinery, juin 2023, p. 241‑246. doi: 10.1145/3593434.3593488.
Auteur
-

Sébastien Bertrand
Doctorant en informatique et cognitique